
TL;DR
- 91% of the SQL injection we found was live in apps that run SAST in their CI pipeline — static analysis in the pipeline didn't stop it reaching production.
- 78% of critical findings were exploitable with no prior access — no login required.
- 42% of applications had at least one broken access control flaw — the most prevalent category in the dataset.
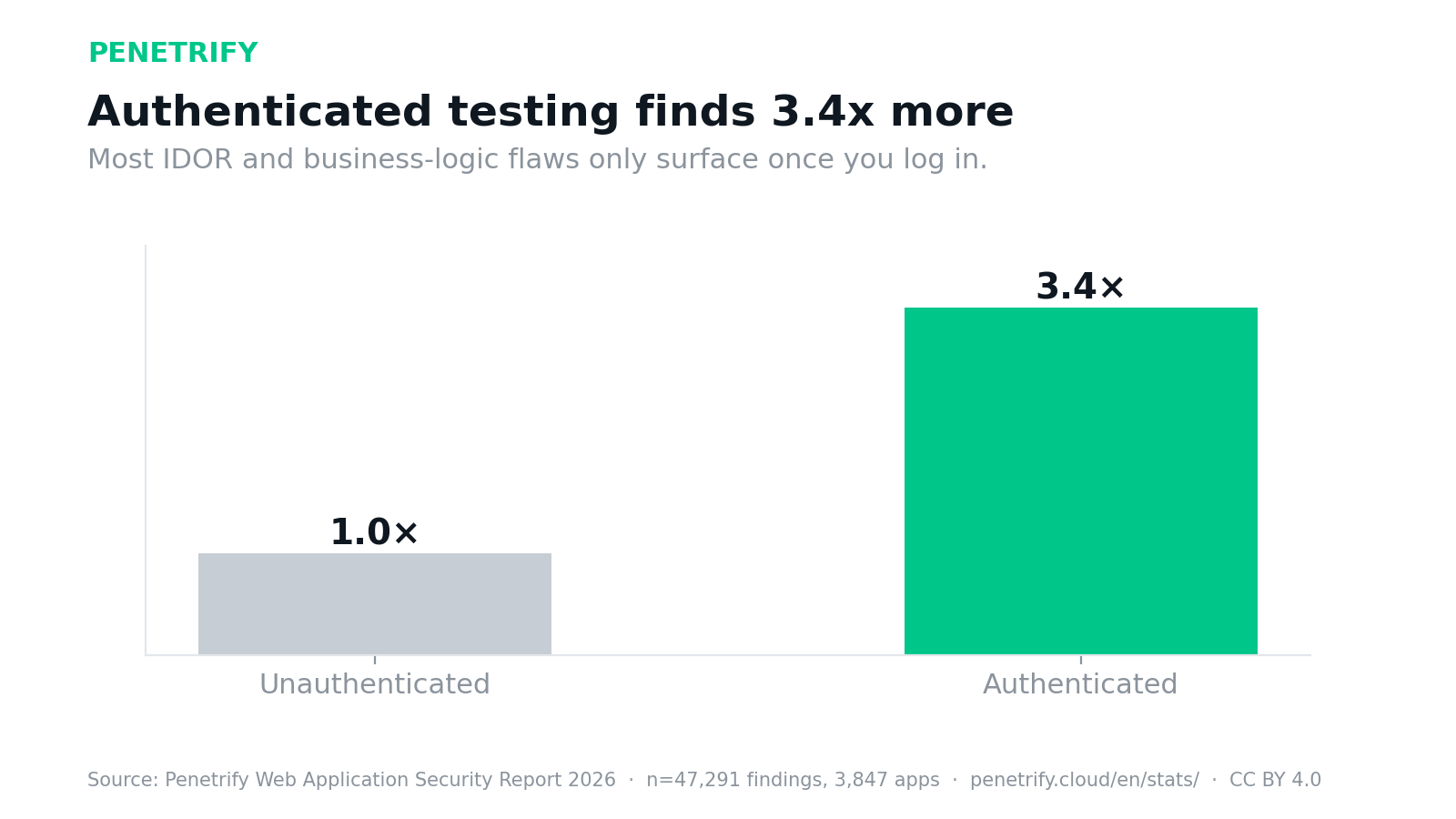
- Authenticated testing surfaced 3.4× more vulnerabilities than unauthenticated.
- Dataset, full methodology, and limitations are below. Raw breakdowns are CC BY 4.0; take what's useful.
The question
Shift-left works: teams scan source code in CI, gate on SAST, and pull in dependency and secrets scanners. So we wanted to answer a narrower, practical question with data rather than opinion: when you actually try to exploit a running application, what do you find that the scanners didn't?
This isn't a product argument — it's a coverage question every AppSec team has. The numbers below come from running an autonomous testing agent that attempts exploitation (not just signature detection) against real applications, then validates each finding by proving it.
Methodology
Dataset. 47,291 findings across 3,847 distinct web applications and APIs, tested between October 2025 and March 2026. Findings are counted at the vulnerability-instance level — one application with five distinct SQL injection points contributes five findings.
"Exploitation-validated" finding. Each finding counted here was confirmed by the agent actually exploiting it — not flagged by signature or heuristic alone. Validation relies on a deterministic oracle: a unique, agent-controlled effect causally produced by its own payload. For injections, the agent triggers an out-of-band interaction (OAST), run on its own dedicated infrastructure, or reads a specific controlled marker (such as the output of SELECT @@version or a pre-planted canary), proving genuine query execution. For authorization flaws, validation is cross-checked: user A's session demonstrably retrieves an object belonging to user B, compared against a ground-truth reference — not merely an HTTP 200 on a manipulated ID. Exploitation is non-destructive: the agent reads only a minimal proof value sufficient to confirm execution, never the underlying dataset, and without modifying or exfiltrating data.
The SAST comparison. This is measured against the subset of apps known to run a SAST gate in their CI pipeline (2,231 of the 3,847, 58%) — a further-narrowed slice of an already self-selected sample. Important caveat: we did not run our own SAST scan over their source code — we only know the pipeline included a SAST step. So the claim is narrow — a SAST-gated pipeline did not prevent the issue from reaching the running app — and it does not establish that SAST failed to detect it. The finding may have been flagged and overridden, suppressed, or fallen outside the tool's language or rule coverage. "SAST" here is whatever single tool and ruleset each team ran.
Privacy. Data is anonymised and aggregated. No PII, no source code, and no identifying details about tested organisations.
Where the vulnerabilities are
By share of all findings: broken access control 34.2%, injection (SQLi/XSS/SSTI) 21.7%, security misconfiguration 18.3%, broken authentication 12.4%, sensitive data exposure 7.8%, vulnerable components 3.4%, other 2.2%. Note the two different denominators: that's 34.2% of all findings, but broken access control affected 42% of apps — the most prevalent category in this dataset.

Severity and exploitability
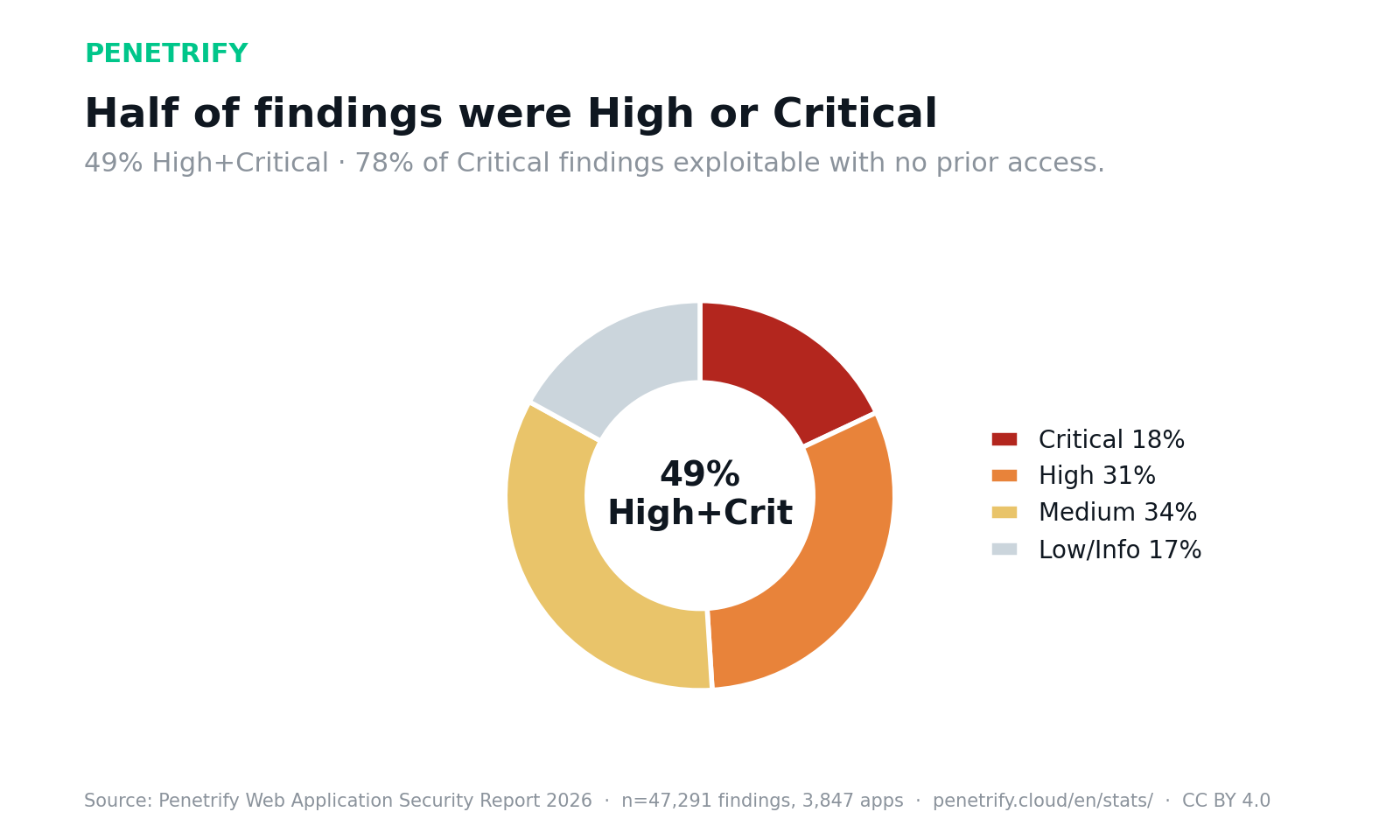
49% of findings were High or Critical (Critical 18%, High 31%, Medium 34%, Low/Info 17%). The number that stood out: 78% of critical findings were exploitable with no prior access — reachable by an unauthenticated attacker, with no foothold required.

What a SAST gate in CI didn't stop
Of the SQL injection we exploited, 91% was in applications that run SAST in their CI pipeline (see the SAST caveat in Methodology — we don't claim SAST failed to detect it, only that a SAST-gated pipeline didn't prevent it reaching production). This isn't a knock on SAST — it's a coverage boundary. Static analysis reasons about source code; injection that depends on runtime data flow, framework behaviour, or composed queries — or that's flagged and then overridden — can still be live and exploitable against the running app.

Why authenticated testing matters
Authenticated testing surfaced 3.4× more vulnerabilities than unauthenticated testing across the dataset. Most broken-object-level-authorization (IDOR) and business-logic flaws simply don't exist until you're logged in and can move between objects and roles. This sits comfortably with the 78% figure above: the critical findings skew to pre-auth bugs an anonymous attacker can reach, while authenticated testing mostly expands the total count — largely with authorization issues that are often high, not critical. Either way, testing only the unauthenticated surface misses most of the high-impact authorization issues.
What this means in practice
A few takeaways that hold regardless of which tools you use:
- SAST is necessary, not sufficient. Pair static analysis with dynamic, exploit-driven testing — they cover different failure modes, and the injection data shows the gap is large.
- Authorization is the dominant real-world risk. Broken access control leads, and 78% of critical issues need no login. Test authenticated, across multiple roles, or you miss most of it.
- Cadence matters. New code — and the issue classes above — ships between point-in-time audits, which is the argument for testing continuously rather than once a quarter.
Limitations — what this data does not show
This is a single-vendor dataset, not a peer-reviewed study. Read it with these caveats:
- Selection bias. These are applications whose teams chose to run an autonomous testing platform — skewed toward startups, SMBs, and SaaS (38% of the sample). It is not a representative sample of the web.
- The agent has blind spots. Autonomous testing is strong on broad, exploit-driven coverage but weaker than a skilled human on novel business logic and deeply context-dependent attack chains. What we found is not everything that's there.
- The SAST comparison is a narrowed subset. It covers only apps that run a SAST gate in CI — a further-narrowed slice of an already self-selected sample, so the selection biases compound — and reflects one SAST tool and ruleset.
- Validation isn't infallible. Exploitation-validation reduces but doesn't eliminate false positives and false negatives.
- Point-in-time. Figures cover October 2025 to March 2026 and shift quarter to quarter.
Data availability
Aggregate data and methodology are published on our Web Application Security Report under CC BY 4.0 — quote, chart, or reproduce with attribution. Happy to share raw category and severity breakdowns or the chart pack on request.
For context, IBM's 2024 Cost of a Data Breach Report puts the average breach at $4.88M — many of which begin with the same web-application weaknesses covered here.